DeepSeek 開源的不是模型,是商業屠殺 ft. DeepSpec
DeepSeek 最近開源了一個東西,第一眼很容易略過——因為它不是一個模型。是 DeepSpec,一套訓練和評測「推測解碼草稿模型」的全家桶。聽起來像後廚的工具,不像菜。
但你想清楚它開源的是「什麼」,會發現這一點都不無聊。它是衝著一個東西去的:別人用資本堆出來的護城河。
先把 AI 想成一塊四層蛋糕
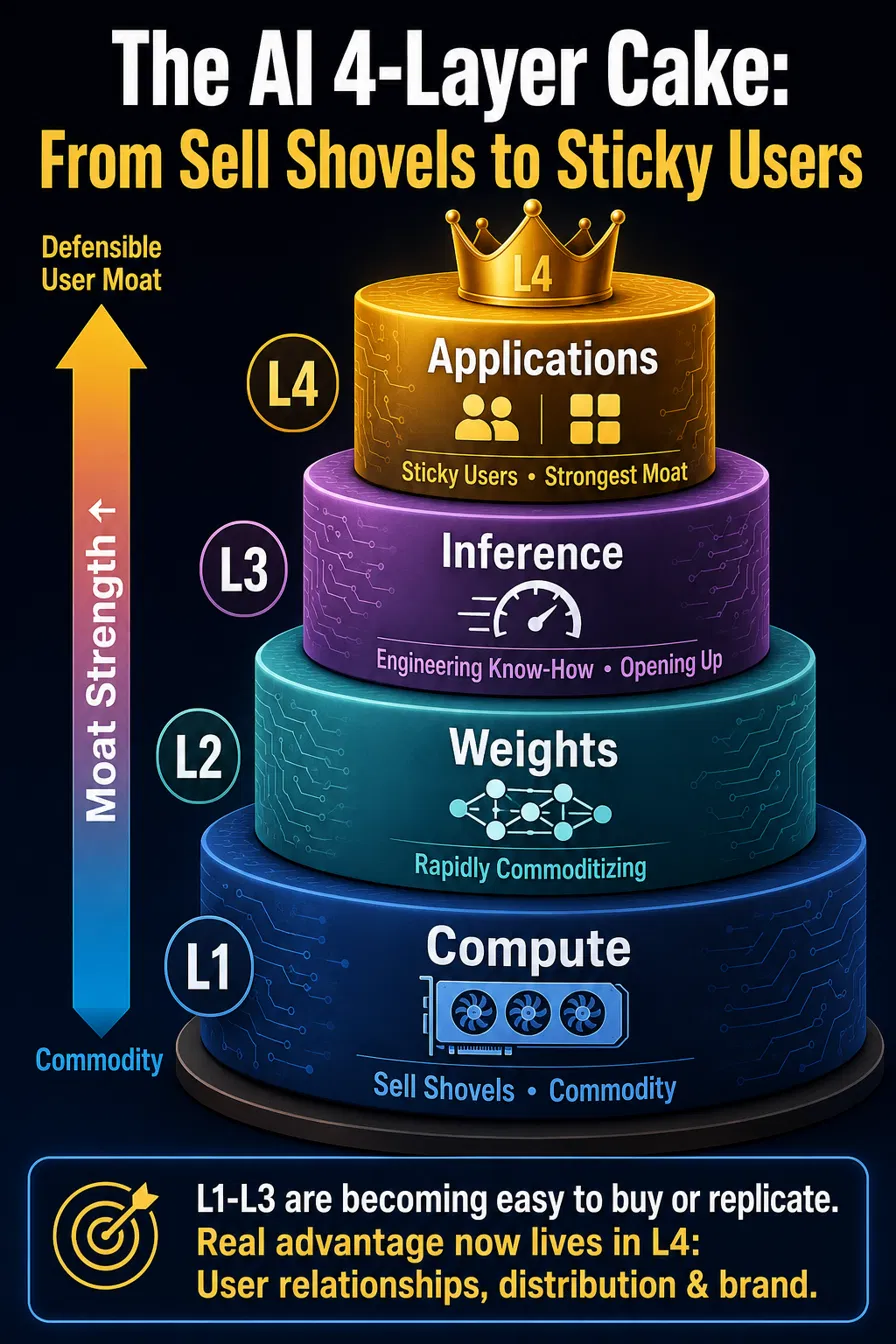
Fig 1 — 四層蛋糕:稀缺從底層的商品,往頂層的用戶護城河爬。
從下到上,越下面越「賣鏟子」,越上面越「黏用戶」:
- L1 算力——跑模型的硬體。GPU、數據中心。你刷卡就租得到 H100,它早就是商品。
- L2 權重——訓練好的模型本身。被 DeepSeek 一路開源,正在快速變商品。
- L3 推論——把同一顆模型跑得又快又便宜的能力。量化、KV 壓縮、推測解碼。這是各家 serving 後廚的 know-how,直到這次被掀開。
- L4 應用——終端產品,抓住通路與用戶。品牌、分銷、敘事。
關鍵動態只有一句:稀缺性沿著這塊蛋糕往上爬。 下面三層誰都做得到的時候,能賺錢的位置只剩最上面那層。
先記住這個結論——下面三層我們這種沒資本的人玩不起,但 L4 不靠資本。文末會回來細講能怎麼打。
DeepSpec 特別在哪:開源的是後廚,不是菜
先講 L3 為什麼是護城河。模型只訓練一次,但之後幾百萬人每天對它發問,每一次發問都要燒算力。難在 LLM 是一個字一個字吐的——每吐一個 token,上兆參數的巨獸就要做一次完整前向計算。逐字、序列、慢。
推測解碼這樣破:讓一顆便宜的草稿模型先猜一串 token,大模型用一次前向平行驗證整串,猜對的就白賺。「快又便宜」的本質,就是一次昂貴前向換到好幾個 token。
而這顆草稿模型怎麼訓練、猜得多準,以前是各家 serving 的機密。DeepSpec 把這份機密整包開源了,MIT 授權、單機八卡就能跑。它量的核心指標是 acceptance(接受率):草稿每猜一串,大模型平均能接受幾個;接受率越高,每次昂貴前向換到的 token 越多,tok/s 才衝得上去。至於它怎麼把這條後廚手藝一路推成商品,等一下專門拆。
換句話說:以前你要嘛自己養一支 serving 團隊摸索半年,要嘛付錢給 Together、Fireworks 那種後廚。現在配方在 GitHub 上,免費。
名詞釐清:serving、inference、post-training
順帶把三個常被混用的詞釘清楚。
Q:serving 就是 inference 嗎?這算 post-training 嗎?
兩個常被混用,精確上不一樣,關係是 serving ⊇ inference。
Inference 是「跑一次模型、算出輸出」這個運作本身——就是 computing:把輸入餵進去、吐出 token。
Serving 是把 inference 產品化、規模化的整套系統:怎麼 batching、怎麼排隊消化成千上萬個用戶請求、auto-scaling、KV cache、API 層、負載平衡。一句話,serving 是一整套伺服「要消耗 token 的人」的客戶服務系統;inference 只是它最核心的那一下計算。
那這算 post-training 嗎?不算——而這是最關鍵的釐清,老實說連我自己都會搞混。
post-training 是預訓練之後對模型做的 SFT / RLHF / RLVR / 蒸餾——這些都會改權重,所以它屬於 L2(權重層),不是 L3。
L3(inference / serving)是部署、執行的階段:不動主模型權重,只是把一顆已經訓好的模型跑得更快更省(量化、KV 壓縮、推測解碼、batching)。DeepSpec 訓練的草稿模型完全不碰大模型——大模型凍著不動,你只是另外養一顆小模型去猜它會講什麼;而且推測解碼是無損的:大模型那一次平行驗證,保證輸出分佈跟它自己慢慢吐完全一致——greedy 解碼下連字都一模一樣;開了隨機採樣則是同一個分佈、不保證同一句——總之品質不打折,只是更快。
所以一句話分界:會改主模型權重的(含 post-training)都算 L2;不碰主模型權重、只外掛輔助結構把它跑快的(草稿模型、量化、KV 壓縮),才是 L3。 草稿模型自己當然也是訓出來的——但它動的不是主模型的一克權重,所以 DeepSpec 穩穩落在 L3。
而且這次一次掃兩層
別漏掉同一時間的另一手。DeepSeek 把 V4-Pro-DSpark 也放上了 Hugging Face——893GB、fp8、MoE 的旗艦模型,而且草稿頭直接焊在上面。
所以這一波不是開源一層,是一次掃兩層:L2(V4 權重)+ L3(DSpark 草稿模型加整套訓練評測配方),同一個禮拜一起丟出來。蛋糕的下三層,現在只剩 L1 還要你真的有錢買卡——而那層你本來就租得到。
DeepSpec 怎麼把整層商品化
退一步問:一個能力要怎樣才會「商品化」?通常得同時滿足四個條件——配方公開、可複現、可量測比較、而且免費綁在下層一起送。 DeepSpec / DSpark 四個全中,這就是機制。拆開講:
一,把黑魔法變成有文件的 pipeline。 草稿模型怎麼訓練、資料怎麼蒐、loss 怎麼設、怎麼對齊 target 分佈,過去是各家後廚的手藝。DeepSpec 把 data prep → train → eval 整條開源、MIT。手藝一旦變成誰都能照抄的文件,就不再是手藝。
二,把它變成可量測、可比較的 benchmark。 這步最狠。DeepSpec 把 DSpark、DFlash、Eagle3 擺在同一個 eval 台上,用同一批任務(GSM8K、HumanEval、LiveCodeBench…)量接受率。一件事一旦有了排行榜,就從「祕密」降級成「工程問題」:大家收斂到同一條最佳實踐,沒人再能靠「我家解碼比較快」收溢價。leaderboard 化 = 商品化。(老實說一句:DSpark 附了自己的論文、宣稱是新方法,但公開 README 沒給對 Eagle3 的正面數字、也沒細講新在哪;所以「DSpark 到底贏多少」目前存疑——但「把這條跑道變成可比的公開賽道」這件事,已經成立。)
三,把成品直接塞進權重包一起送。 HF 上那顆 DeepSeek-V4-Pro-DSpark,官方自己寫明「不是新模型,是同一個 checkpoint 多掛一個推測解碼模組」——加速器預裝在權重裡,連「自己訓一顆草稿」的門檻都省了。下層免費送的時候順手把上層也附上,是把商品化往上推一格的標準動作。
四,再疊 V4 本體的便宜 attention,雙向砍成本。 DSpark 砍的是解碼步數(一次前向換多個 token);V4 本體用 CSA + HCA 的混合注意力砍的是每步的算力與記憶體——官方數字:百萬 token 長度下,單 token 推論只要 V3.2 的 27% FLOPs、10% KV cache。兩條軸一起壓,L3 的成本曲線整個塌下來。
結果:誰都能用同一套配方、同一顆草稿,跑出同一級的 tok/s 與 $/token。L3 的「演算法溢價」被壓平——這就是商品化。
不過得誠實標一條邊界:被商品化的是「演算法層」,不是「營運層」。 「配方公開」跟「你能在規模上又快又便宜地跑」之間,還隔著沒被填平的護城河:GPU 機隊利用率、大規模 batching、自家 CUDA kernel、延遲 SLA、真實電費與硬體攤提。DeepSpec 掀開的是推測解碼這塊演算法 know-how;serving-at-scale 的營運 know-how還是有人賺得到。所以 L3 是被放了一半的水,不是全乾——文末那張圖把 L3 標成「這次打到」是對的,但它不會像 L2 那樣塌到底。
那到底為了什麼?
開源一套 serving 配方,DeepSeek 圖什麼?把所有事情想清楚,我的結論是:它在拆的,是美國 AI 用資本堆出來的優勢。
現在美國這邊的融資尺寸已經難以匹敵。數百億美金的單輪紀錄,頂部的 OpenAI、Anthropic,收入很大、開銷很大、融資更大。這整個故事的地基是一句話:「玩 AI 要燒這麼多錢。」 估值、融資、人才,全長在這句話上。
DeepSeek 做的每一件事,都在拆這句話:
- 開源權重(L2),「你要花幾十億訓練模型」這句就鬆了。
- 開源 serving 配方(L3),「你要養一支頂尖後廚才跑得便宜」這句也鬆了。
- 一次掃兩層,鬆的速度直接翻倍。
它不需要、也沒辦法去開源 OpenAI 的資產負債表。但它可以做一件更狠的事:讓那張資產負債表變得不重要。 當下面三層都免費、都可複製,「要燒這麼多錢才玩得起」的敘事就崩了——而那個敘事,正是數百億估值的地基。
這不是慈善,是戰術。你沒法在資本市場上跟美國拼融資尺寸,那就把「需要那麼多資本」這個前提本身打掉。
稀缺往上爬:L1 早是商品,這次 DeepSpec + V4 一次掃掉 L2 與 L3,護城河只剩最上面的 L4。
同一個劇本,演了幾百年
了解 DeepSpec 之後,我一直在想一個問題:到底哪些東西夠稀缺,一年、三年內都不會被複製? 這很難,因為稀缺往往綁在門檻上——硬體、資本——而當 intelligence 本身都被打平,一般人能走的高門檻路就更少了。
但「稀缺往上跑」其實只是表象。真正該問的是:你身上哪個長處,是別人複製不了的? 那個答案,通常落在最靠近需求、最靠近用戶信任的地方。
把這個視角套到歷史上,你會發現同一個劇本演過很多次:某一層被標準化、變成商品,卡在那層的人毛利歸零,而價值跑去「還沒被複製」的上一層。
| 產業 | 被商品化的那層 | 卡在那層的人 | 價值跑去哪 |
|---|---|---|---|
| 電信 | 頻寬(3G→4G→5G→吃到飽) | 電信商:毛利越壓越低,還得砸錢標頻譜、建網、買牌照 | IM(WhatsApp、Telegram)——簡訊與通話被吃掉 |
| PC / 作業系統 | 硬體(相容機割喉戰) | Compaq、Dell 拼價格,毛利歸零 | 軟體(Microsoft)——Bill Gates 不造硬體 |
| 雲端運算 | 伺服器(AWS 把算力變水電) | 自建機房失去意義 | SaaS(Salesforce、Snowflake)——不擁有伺服器,擁有 workflow |
| 貨櫃航運 | 運費(標準化把成本砍到趨近零) | 純航運公司只能互相殺價 | 通路與需求(Walmart、Amazon)——不擁有船,擁有用戶 |
| AI(現在) | L1 算力 → L2 權重 → L3 推論(DeepSpec 正在掀) | 守在「我家解碼比較快」的人 | L4 應用 / 分銷 / 信任 |
每一列都是同一句話:會被標準化的那層,終究是商品;能長期收租的,是還沒被標準化、而且離用戶最近的那層。
那 NVIDIA 呢?——看似反例,其實同一條規律
有人會說:NVIDIA 的價值明明在最底層,這不就反了嗎?不。NVIDIA 不是反例,是同一條規律停在不同位置:它的 GPU 製造加上 CUDA 生態,短期沒人複製得了——所以稀缺暫時停在它那層。
但「短期」是關鍵詞。Google 做 TPU、OpenAI 自研晶片、xAI 也要自研晶片,大家都想擺脫被 NVIDIA 掐脖子。長期看 NVIDIA 的市佔大概會往下;而不管最後誰來設計晶片,還是得找台積電代工。所以真正可能「無與倫比」的天花板,也許是台積電那層的製造稀缺——它離「不可複製」更近。
對你我這種會用 AI 的 builder,意義很直接:L1 有 NVIDIA、台積電這種製造門檻守著價值,但那道門檻你買不進去;而 L2、L3 正在快速可複製化——DeepSpec 就是 L3 可複製化的鐵證。所以你能下注的稀缺,只剩 L4。
DeepSpec 只是從另一個方向證明同一件事:L3 的地板正在塌,逼著稀缺往 L4 搬。
壁壘只剩 L4——剛好是我們打得起的仗
那 L4 的護城河具體長什麼樣?四種型態,每種對應一個動作:
- 通路(distribution)——別讓用戶來找你,去他們已經在的地方。把每個入口當成長期分銷節點,不是一次性廣告。
- 敘事(narrative)——誰定義這個品類怎麼被談論,誰就贏。固定產出公開研究,成為這條賽道被引用的參考點(那個品類的 Stratechery)。產品會被商品化,敘事不會。
- 網路效應(network effects)——把產品做成多人遊戲:排行榜、跟單、推薦迴圈。用戶價值隨人數成長,這是 L4 最硬的鎖。單機體驗沒有網路效應,社交化才有。
- 信任(trust)——尤其在加密圈,信任最稀缺。用可驗證的技術(web proofs / zkTLS)讓結算可被驗證,把「可信」做成品牌兼技術差異化。別人抄得了 UI,抄不了你的信任層。
再加一個常被忽略的第五型:在地化——對某個市場、語言、社群的原生理解。大廠最不耐煩做的,正好是你的壁壘。
我自己的賭注就壓在這上面:一個 Telegram-native 的預測市場,核心不是更炫的 UI,是上面這幾條的組合。具體怎麼接,是另一篇的事。
但「往上」其實是錯的軸
到這裡,我都把 DeepSeek 講成「L2、L3 被商品化」的證據。但其實有個更利的角度:DeepSeek 不是受害者,是發動者。
Joel Spolsky 有句老話:commoditize your complement——把你的互補品壓到趨近免費,需求就會湧向你還握著的那層。微軟把硬體(它的互補品)打成白菜價,需求湧向作業系統;Amazon、Walmart 把上游壓平,需求湧向通路。回頭看上面那張表,每個贏家幾乎都不是「剛好站在上層」,而是「主動把下層商品化掉」的那個。
DeepSeek 開源模型與推論,不是放棄價值,是主動炸平美國實驗室的護城河——同時收割中文生態的引力、人才、地緣槓桿與敘事主導權。最大的價值,常常被「主動發動商品化的人」拿走,不是被動站上層的人。
所以真正的逼問,不是「我站在哪一層」,而是:「我能不能成為某一層的商品化發動者?」 對我自己就是:Portex 能不能把 Polymarket 的某一塊商品化掉,讓需求湧向我?那才是值得花三年想的問題。
文末與可能的總結
把整件事收成一句:每當一層被標準化、變得可複製,它就從護城河降級成商品;能長期收租的,是還沒被標準化、最靠近需求與信任的那層——或者,是主動把別層商品化掉的那個人。
於是三件事:
一,別把「燒了多少錢」當護城河。 投入規模是成本,不是壁壘。會被一個 MIT repo 抹平的優勢,本來就不是優勢。
二,別只問「我站哪一層」。 會被標準化的那層終究是商品;更利的問題是你能不能主動發動商品化,把互補品壓平、讓需求湧向你還握著的那層。
三,如果你在做東西: 想清楚你對哪群人、哪個市場有別人沒有的理解。算力租得到、權重抓得到、serving 配方 clone 得到;買不到、抄不走的,只有 L4——而最強的玩法,是成為那塊的發動者。
DeepSeek 這一刀,砍的不是模型的價格,是「資本能不能買到贏面」這個假設。
方法與侷限:技術名詞與數字來自 DeepSpec 的公開 repo 與 V4-Pro-DSpark 的 model card(MIT,2026-06);acceptance、benchmark 任務、893GB / fp8 等以官方為準。資本市場的部分是我的判讀,不是投資建議。
References
- DeepSpec(推測解碼訓練 + 評測全家桶,含 DSpark / DFlash / Eagle3)— github.com/deepseek-ai/DeepSpec
- DeepSeek-V4-Pro-DSpark(旗艦模型 + 內建草稿頭)— huggingface.co/deepseek-ai/DeepSeek-V4-Pro-DSpark
- Joel Spolsky,「commoditize your complement」的出處(Strategy Letter V)— www.joelonsoftware.com/2002/06/12/strategy-letter-v
DeepSeek didn't open-source a model — it open-sourced a massacre ft. DeepSpec
DeepSeek just open-sourced something. Easy to ignore at first. It's not a model.
It's DeepSpec. A full toolkit for training and evaluating speculative-decoding draft models. Back-kitchen tools, not the meal.
Look at what they actually released and it stops feeling small. They're going after one thing: the moat someone else built out of capital.
Think of AI as a four-layer cake
Fig 1 — The four-layer cake: scarcity climbs from commodity at the base to a user moat on top.
Bottom to top. Lower layers sell shovels. Upper layers own users.
- L1 Compute — the hardware that runs models. GPUs. Data centers. Rent an H100 with a card. Already a commodity.
- L2 Weights — the trained model itself. DeepSeek keeps open-sourcing them. Commoditizing fast.
- L3 Inference — run the same model faster and cheaper. Quantization. KV compression. Speculative decoding. This was each lab's private serving know-how. Not anymore.
- L4 Applications — the products that reach users. Brand. Distribution. Narrative.
One rule: scarcity moves up. Once anyone can do the bottom three layers, the only money left sits at the top.
Hold onto that conclusion — the bottom three layers are out of reach for those of us without capital, but L4 needs none. I'll come back at the end to how you actually fight there.
What makes DeepSpec special: it open-sources the back-kitchen, not the dish
Why L3 is a moat. You train a model once. After that, millions of people query it every day. Every query burns compute.
The pain is built in. LLMs emit one token at a time. Each token forces a full forward pass over a trillion-parameter beast. Token by token. Sequential. Slow.
Speculative decoding breaks the pattern. A cheap draft model guesses a run of tokens. The big model verifies the whole run with one forward pass, in parallel. Hits are free. "Fast and cheap" just means one expensive pass buys you several tokens.
How you train that draft model — and how well it guesses — used to be each serving team's secret. DeepSpec open-sourced the whole thing under MIT. It runs on a single 8-GPU machine. The metric it measures is acceptance: for every run the draft guesses, how many tokens the big model keeps on average. Higher acceptance, more tokens per expensive pass, higher tok/s. How they turned this back-kitchen craft into a commodity — I'll break it down in a moment.
Put simply: before, you either spent six months staffing your own serving team or paid a back-kitchen like Together or Fireworks. Now the recipe is on GitHub. Free.
Getting the terms straight: serving, inference, post-training
Three terms people blur together.
Q: Is serving the same as inference? And does this count as post-training?
They overlap in practice, but the clean relationship is serving ⊇ inference.
Inference is the raw act: run the model once and compute the output. Pure compute. Tokens in, tokens out.
Serving is the full production system. Batching. Queuing thousands of requests. Auto-scaling. KV cache. API layer. Load balancing. In one line, serving is the whole customer-service system for "people who spend tokens." Inference is just the core calculation inside it.
Does it count as post-training? No — and this is the clarification that matters most, the one I trip over myself.
Post-training happens after pre-training: SFT, RLHF, RLVR, distillation. These all change weights. So it belongs to L2 (the weights layer), not L3.
L3 (inference / serving) is the deployment and execution stage. The base model's weights stay frozen; you just make an already-trained model faster and cheaper — quantization, KV compression, speculative decoding, batching. DeepSpec's draft model never touches the big model: the big model stays frozen, you raise a small separate model to guess what it will say. And speculative decoding is lossless — the verification pass guarantees the same output distribution the big model would produce on its own: bit-identical under greedy decoding, same distribution (not necessarily the same sample) under temperature sampling. No quality haircut, just sooner.
The dividing line in one sentence: anything that changes the base model's weights (post-training included) is L2; anything that leaves them alone and bolts on auxiliary machinery to run it faster (draft models, quantization, KV compression) is L3. Yes, the draft model gets trained too — but it never moves a gram of the base model's weights. DeepSpec lives cleanly in L3.
And this time it sweeps two layers at once
Don't miss the other move they made at the same time. DeepSeek dropped V4-Pro-DSpark on Hugging Face too. 893GB. fp8. MoE flagship. And they welded the draft head straight on top.
So this drop isn't one layer open-sourced. It's two at once: L2 (the V4 weights) + L3 (the DSpark draft model plus the full training-and-eval recipe). Same week. Of the bottom three layers of the cake, only L1 still takes real money to buy cards — and that layer you could always rent.
How DeepSpec commoditizes the whole layer
Step back. When does a capability turn into a commodity? It needs four things at once. The recipe is public. It's reproducible. It's measurable and comparable. And it ships free, bundled with the layer below. DeepSpec and DSpark hit all four. That's the mechanism.
1. Turn black magic into a documented pipeline. How you train a draft model. How you collect the data. The loss setup. Aligning to the target distribution. All of it used to be back-kitchen craft. DeepSpec open-sourced the full data prep → train → eval chain under MIT. Once a craft becomes a document anyone can copy, it stops being a craft.
2. Turn it into a measurable, comparable benchmark. This one hurts. They put DSpark, DFlash, and Eagle3 on the same eval bench, scored by acceptance across the same tasks (GSM8K, HumanEval, LiveCodeBench…). The moment something has a leaderboard, it drops from "secret" to "engineering problem": teams converge on the same best practice, and no one charges a premium for "our decoding is faster." Leaderboard = commoditize. (One honest note: DSpark ships with its own paper and claims to be a new method, but the public README gives no head-to-head numbers against Eagle3 and doesn't spell out what's new. So how much DSpark actually wins by is unproven. What's certain is the track is now a public, comparable race.)
3. Ship the finished piece inside the weights. The HF card for DeepSeek-V4-Pro-DSpark states it plainly: "not a new model — the same checkpoint with a speculative-decoding module attached." The accelerator is pre-installed in the weights; even "train your own draft" is off your plate. Giving away the layer below and tossing in the layer above for free is the standard move for pushing commoditization up a notch.
4. Stack V4's cheap attention on top, cutting cost from both ends. DSpark cuts decode steps — one forward pass, multiple tokens. The V4 model itself, with its CSA + HCA hybrid attention, cuts compute and memory per step — official numbers: at million-token context, single-token inference takes just 27% of the FLOPs and 10% of the KV cache of V3.2. Squeeze both axes and L3's cost curve caves in.
The result: anyone can hit the same tok/s and $/token with the same recipe and the same draft. L3's "algorithm premium" gets flattened — that's commoditization.
But one boundary stays real: what gets commoditized is the algorithm layer, not the operations layer. "The recipe is public" doesn't equal "you can run it fast and cheap at scale." The moat that remains: GPU-fleet utilization, large-scale batching, in-house CUDA kernels, latency SLAs, real power costs and hardware depreciation. DeepSpec pulled back the curtain on the algorithmic know-how of speculative decoding; the operational know-how of serving-at-scale still earns its keep. So L3 is half-drained, not bone-dry — marking L3 as "hit this drop" in the diagram below is fair, but it won't collapse all the way like L2.
So what are they after?
DeepSeek open-sourced a serving recipe. What's the play? Work through the pieces and the answer is simple: they're tearing down the advantage US AI built by piling up capital.
US rounds are already impossible to match. Record single rounds in the tens of billions. At the top, OpenAI and Anthropic run big revenue, bigger burn, and raise more still. The whole story rests on one line: "AI costs a fortune to play." Valuations, fundraising, talent — all of it grows from that sentence.
DeepSeek attacks that sentence with everything it ships:
- Open-source the weights (L2) and "you need billions to train a model" starts to crack.
- Open-source the serving recipe (L3) and "you need a top crew just to run it cheap" cracks too.
- Hit both layers at once and the cracks spread twice as fast.
It can't open-source OpenAI's balance sheet. No one can. But it can do something sharper: make that balance sheet matter less. Once the layers below are free and copyable, the story that "you need to burn serious money to compete" collapses — and that story is what holds up the hundreds-of-billions valuations.
This isn't charity. It's tactics. You can't out-raise the US on size, so you blow up the premise that you need that much capital at all.
Scarcity climbs: L1 was always a commodity; this drop sweeps L2 and L3 at once, leaving the moat only at L4 on top.
The same script, running for centuries
DeepSpec left me stuck on one question: what actually stays scarce? What won't get copied in a year, or three? It's hard to answer. Scarcity usually sits behind a real barrier — hardware, capital — and once intelligence itself levels out, fewer high walls remain.
"Scarcity moves up" is just the surface view. The real question is: what strength do you have that no one else can copy? That answer almost always lives closest to demand. Closest to a user's trust.
Run the same lens over history and the script repeats: a layer gets standardized, turns into a commodity, the players stuck there watch margins go to zero, and the value shifts to the layer above that hasn't been copied yet.
| Industry | The layer that got commoditized | Who got stuck there | Where the value went |
|---|---|---|---|
| Telecom | Bandwidth (3G→4G→5G→unlimited) | Carriers: margins squeezed thinner, still paying for spectrum, buildout, licenses | IM (WhatsApp, Telegram) — SMS and calls eaten alive |
| PC / OS | Hardware (clone price war) | Compaq, Dell racing on price, margins to zero | Software (Microsoft) — Gates never built hardware |
| Cloud | Servers (AWS turned compute into a utility) | Self-built data centers lost their point | SaaS (Salesforce, Snowflake) — own the workflow, not the servers |
| Container shipping | Freight (standardization cut cost toward zero) | Pure shippers left to undercut each other | Distribution & demand (Walmart, Amazon) — own the users, not the ships |
| AI (now) | L1 compute → L2 weights → L3 inference (DeepSpec prying it open) | Whoever guards "my decoding is faster" | L4 application / distribution / trust |
Every row says the same thing: the layer that gets standardized becomes a commodity; the one that keeps collecting rent is the one not yet standardized — and closest to the user.
But what about NVIDIA? — a seeming exception that proves the rule
People will say: NVIDIA's value sits at the very bottom — doesn't that break the pattern? No. NVIDIA isn't an exception, it's the same rule, just parked at a different layer: its GPUs plus the CUDA ecosystem can't be copied right now, so scarcity sits there for the moment.
"Right now" is doing all the work. Google builds TPUs. OpenAI is making its own chips. xAI wants its own silicon too. Everyone wants out from under NVIDIA's thumb. Over time NVIDIA's share probably drifts down. But whoever ends up designing the chips still needs TSMC to build them. So the truly un-copyable ceiling may sit at TSMC's manufacturing layer — the one closest to impossible to replicate.
For builders like us who actually use AI, the point is simple: L1 has manufacturing barriers (NVIDIA, TSMC) you can't buy your way past, while L2 and L3 are commoditizing fast — DeepSpec is the clearest proof that L3 can be cloned. So the only scarcity you can actually bet on is L4.
DeepSpec just shows the same thing from another angle: the floor under L3 is caving in, pushing scarcity up to L4.
The moat is only L4 now — exactly the fight we can win
So what does an L4 moat actually look like? Four forms, each matched to one move:
- Distribution — don't wait for users to find you, go where they already are. Treat every entry point as a long-term distribution node, not a one-off ad.
- Narrative — whoever sets how a category gets talked about wins. Ship public research at a steady pace until you're the reference people cite in this lane (the Stratechery of your category). Products get commoditized; narrative doesn't.
- Network effects — turn the product into a multiplayer game: leaderboards, copy-trading, referral loops. User value grows with the headcount — L4's hardest lock. A single-player experience has none; a social one does.
- Trust — especially in crypto, trust is the scarcest thing. Use verifiable tech (web proofs / zkTLS) to make settlement auditable, and turn "trustworthy" into both a brand and a technical edge. Anyone can copy your UI; they can't copy your trust layer.
Add a fifth that gets ignored: localization — real native understanding of one specific market, language, or community. The thing big labs are always too impatient to do is exactly your moat.
My own bet rides on this: a Telegram-native prediction market, where the core isn't a flashier UI but the mix of the above. How it actually gets wired is another post.
But "up" is the wrong axis
Up to here I've framed DeepSeek as proof that L2 and L3 got commoditized. There's a sharper view: DeepSeek isn't the victim, it's the instigator.
Joel Spolsky's old line: commoditize your complement. Drive the thing that complements you toward free, and demand rushes to the layer you still control. Microsoft turned hardware into a low-margin commodity, and demand flowed to the OS; Amazon and Walmart flattened their upstream, and demand flowed to the channel. Look at the table again — almost every winner wasn't "the one who happened to sit on top," it was the one who actively commoditized the layer below.
DeepSeek open-sourcing models and inference isn't giving up value, it's deliberately blowing up the moat around the US labs — while harvesting the gravity, talent, geopolitical leverage, and narrative power of the Chinese-language ecosystem. The biggest value usually goes to the one who starts the commoditization, not the one passively sitting on top.
So the real question isn't "which layer am I on," it's: "can I be the one who commoditizes a layer?" For me, concretely: can Portex commoditize some slice of Polymarket so that demand moves toward what I hold? That's the question worth three years.
So what
Boil it down to one line: any layer that gets standardized and replicable drops from moat to commodity; what keeps collecting rent long-term is the layer not yet standardized and closest to demand and trust — or the player who actively commoditizes everyone else's layer.
So three things:
One: don't mistake "how much money got burned" for a moat. Spend is a cost, not a wall. An edge that one MIT repo can erase was never an edge.
Two: don't just ask "which layer am I on." The layer that gets standardized becomes a commodity; the sharper question is whether you can be the instigator — commoditize your complement and pull demand toward the layer you still own.
Three, if you're building: get clear on which people, which market you understand in a way no one else does. Compute you can rent. Weights you can grab. Serving recipes you can clone. The only thing you can't buy or copy is L4 — and the strongest move is to become the one who commoditizes that complement.
DeepSeek didn't just cut the price of the model. It cut the assumption that capital can buy you the outcome.
Method & limits: technical names and numbers come from the public DeepSpec repo and the V4-Pro-DSpark model card (MIT, 2026-06); treat acceptance, the benchmark tasks, and the 893GB / fp8 figures as per the official source. The capital-markets read is my interpretation, not investment advice.
References
- DeepSpec (speculative-decoding training + eval toolkit, incl. DSpark / DFlash / Eagle3) — github.com/deepseek-ai/DeepSpec
- DeepSeek-V4-Pro-DSpark (flagship model with a built-in draft head) — huggingface.co/deepseek-ai/DeepSeek-V4-Pro-DSpark
- Joel Spolsky, origin of "commoditize your complement" (Strategy Letter V) — www.joelonsoftware.com/2002/06/12/strategy-letter-v